Dobby Diesel
12 Feb 2022


A great shot of an 'ol dog of mine and my sister. Taken back when I was in high school using a 35mm film camera.
Ever need to know your IP but Google is split tunneled or otherwise won't do? Want it in JSON?
https://www.3-4.us/

A few FACs mentioned in this post are still available. Just let me know if you want a free one!

The full command docs for the CTP interface on the Crestron DSP-1283 - v1.00.272.033 (August 23 2018). Generated using this tool with the instructions on this post.
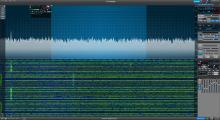
Just a tad bit of QRM here. I suspect it's the battery charger I'm using as a temporary power supply. Normally I have a bunch of filters between the radio and the power system too. That's also missing. Once it's reinstalled the problem should go away. I hope. Lest it's something harder to fix...

General Request Form
The first 50 people to request a coin, with priority given to streamers, get a coin!
Donation Request Form
Make a donation to Paulson McIntyre's Extra Life - The top 50 donors get a coin!
Note: Frequency is subject to change. Although it's been quite a while without issue so it's probably fine here.
Frequency: 145.785 (Simplex)
C4FM ID: 00 (required for C4FM/Wires-X)
Location: Sterling, Va, USA
Grid Square: FM19ha
Station Call: KG4TIH
WIRES-X Node: KG4TIH-ND3 (71429)
Default Room: VA-Sterling (28558)
Transmit Power: 40w
Coordination: N/A
After a bit of moving hardware around my 449.375 Wires-X repeater is back online.
Frequency: 449.375-
Tone: 110.9hz (required for analog)
C4FM ID: 00 (required for C4FM/Wires-X)
Location: Sterling, Va, USA
Grid Square: FM19ha
Station Call: KG4TIH
WIRES-X Node: KG4TIH-ND (18558)
Default Room: VIRGINIA (21625)
Transmit Power: 50w
Coordination: TMARC


{kind=link}
{kind=link}
{kind=link}